




GraphQL is an open-source query language developed by Facebook in 2015 and it is built on the graph data structure. Many big companies are adopting GraphQL besides Facebook, including GitHub, Pinterest, Twitter, Sky, The New York Times, Shopify, Yelp and many others.
In this article, we will learn what is GraphQL and how it could entirely replace REST APIs. We will also see how GraphQL works and its salient features.
Let’s go back to the basics before we deep dive into the world of GraphQL.
REST APIs
REST (Representational state transfer) is the widely used web architecture as it is flexible and simple to use. It is a convention used to manipulate the collection of data hosted on the server. With common rules around HTTP request methods and uniform URL structure, it is used for creating, updating, reading, and deleting the data on the server.
HTTP Methods
HyperText Transfer Protocol (HTTP) is a stateless protocol, which means that the client and server know how to handle the data for each individual instance of a request. Once the browser initiates the request, the server will send a response back to the client. On every request initialized, a new connection is established between client and server. The HTTP verbs are GET, POST, PUT, PATCH, DELETE.
- GET: It is used to retrieve all the information from the server using the URI and should not modify any of the data
- POST: It is used to send data to the server and to create new resources
- PATCH: It is used to update and partially modify the resource
- PUT: It is used to replace the resource entirely, unlike the PATCH method
- DELETE: This will delete the resource
Thinking in Graphs
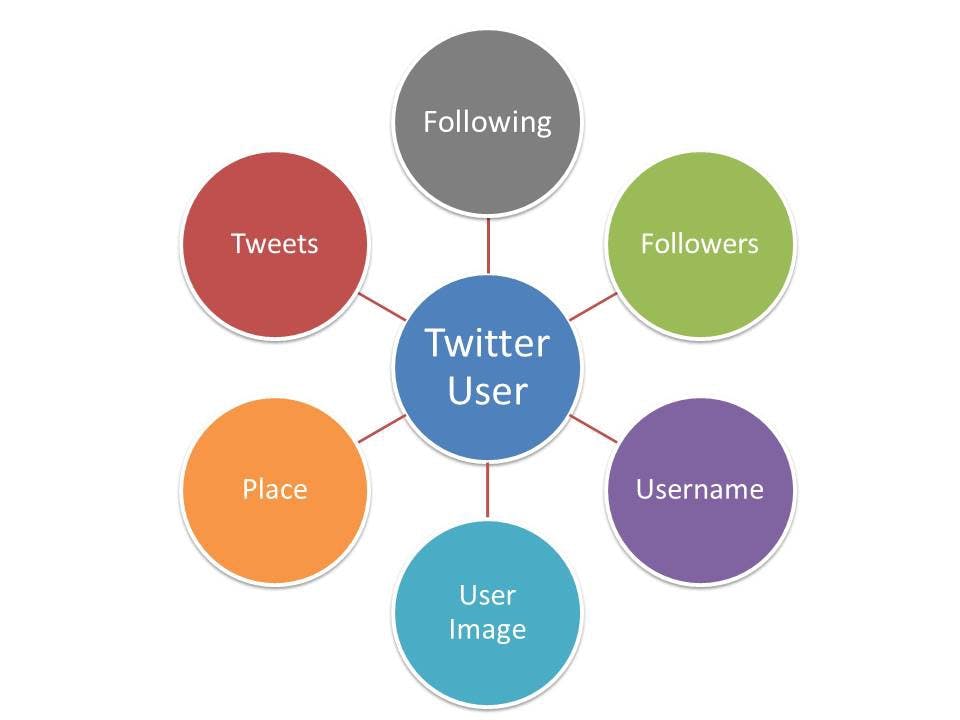
As seen in the graph, we have a Twitter user. This user has a username, image, place, tweets, followers, and following. We will have API and routes for fetching the resources for various scenarios.
Let us consider below routes which will be accessible by the user:
Follower of a user: /user/1/followers
Tweets of a follower of the user: /user/1/followers/followerNo1/tweet/content
Tweets of the people user follows: /user/1/followers/followerNo1/tweet/content
User whom he is following: /user/following
We might have even more convoluted internal routing with various endpoints to access the resources, which may increase the complexity for understanding an API for the developer.
While figuring out how many APIs above application consumes, you will:
- End up with a lot of endpoints
- Create a heavyweight application
- Might not have separation of concerns
- API endpoints will create a complex REST structure
- Loose reliability on the results it provides
Now, Let’s see the advantage of GraphQL architecture over REST APIs and how GraphQL can help us in tackling the above restful routing.
What is GraphQL?
A Graph is a data structure that contains nodes and a relationship between two nodes which is referred to as edges.
Let’s look at some of GraphQL’s salient features:
- GraphQL is strongly-typed, which ensures that the query is valid within the GraphQL type system before execution, i.e. at development time, the server can make certain guarantees on the structure of the response, which makes GraphQL powerful.
- GraphQL provides an efficient (no over-fetching and under-fetching of the data) and more understandable way to consume APIS
- It can be used with any backend framework or programming language
- It helps to add new fields and types to GraphQL API without impacting your existing queries and without creating several versions of the same API
- GraphQL exposes a single endpoint
- GraphQL is self-documenting
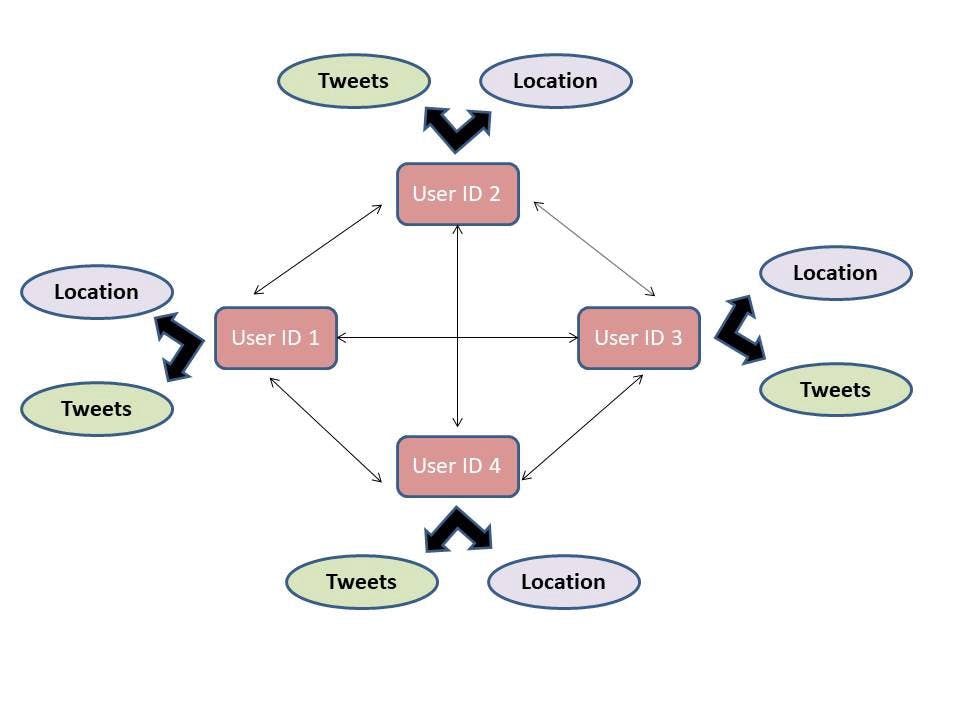
The image shown above is a graph which shows all the relations of our application and how the data is structured into the graph. This will help us understand how GraphQL works with the graph data structure.
We can utilize any databases like MongoDB, MySQL, PostgreSQL without changing any data structure
How do we access the graph via GraphQL?
GraphQL will traverse to a particular record which is called as the root node and instruct it to get all the details of that record.
Example:
We can take any user, let’s say a user with ID 1 and get the data of its associated follower (let say a user with ID 2). Let’s write a piece of GraphQL query to show how to access the same.
query{
user(id:"1"){
users{
tweet{
content
}
}
}
}
Here, we are asking GraphQL to walk to the graph from the root node which is the user object with an argument as id:1 and access the content of the follower’s tweet.
GraphQL Queries
In this section, you’ll learn how a GraphQL query is composed.
The concepts I’ll introduce are:
- Fields
- Arguments
- Aliases
- Fragments
- Variables
- Directives
- Fields
Let’s look at a simple GraphQL query:
{
user {
name
}
}
{
"data": {
"user": {
"name": "foo"
}
}
}
- In this query, you see 2 fields. The field user returns an Object which has another field in it, a String type.
- We have asked GraphQL server to return the user object with its name but we could also have a followers field in the user that lists the followers of that user.
Arguments
You can pass the argument to specify which user we want to reference.
Example:
{
user(id: "1") {
name
}
}
We pass an id, but we could as well pass a name argument, assuming the API has the feature to return with this kind of response We could also have a limit argument, to specify how many followers we want the API to return.
{
user(id: "1") {
name
followers(limit: 50)
}
}
Aliases
You can ask GraphQL API to return a field with a different name.
Example:
{
accholder: user(id: "1") {
firstname: name
}
}
{
"data": {
"accholder": {
"firstname": "john"
}
}
}
{
first_user: tweet(id: "1") {
tweet_content: content
}
second_user: tweet(id: "2") {
tweet_content: content
}
}
The two tweet fields would have conflicted, but since we can alias them to different names, we can get both results in one request from the same endpoint
Fragments
- In the above query, we replicated the tweet structure. Fragments will allow us to specify the structure with many fields.
- The concept of fragments is frequently used to split complicated application data requirements into smaller chunks, especially when you need to combine lots of UI components with different fragments into one initial data fetch.
Example:
{
leftComparison: tweet(id: 1) {
...comparisonFields
}
rightComparison: tweet(id: 2) {
...comparisonFields
}
}
fragment comparisonFields on tweet {
userName
userHandle
date
body
repliesCount
likes
}
The above API will return the following response:
{
"data": {
"leftComparison": {
userName: "foo",
userHandle: "@foo",
date: "2019-05-01",
body: "Life is good",
repliesCount: 10,
tweetsCount: 200,
likes: 500,
},
"rightComparison": {
userName: "boo",
userHandle: "@boo",
date: "2018-05-01",
body: "This blog is awesome",
repliesCount: 15,
tweetsCount: 500,
likes: 700
}
}
Variables
GraphQL variables are the way to dynamically specify a value that is used inside a query. This will be good as it will replace the static value in the query. As you have seen above, we have passed our arguments inside the query string. We will be passing the arguments with a $variable.
Example:
We added the user id as the string inside the query
{
accholder: user(id: "1") {
fullname: name
}
}
We will add the variable and replace the static value. Same can be written as:
query GetAccHolder($id: String) {
accholder: user(id: $id) {
fullname: name
}
}
{
"id": "1"
}
Here, GetAccHolder is the named function. It is useful to give named function when you get lots of queries in your application.
Default Variable:
We can specify the default value for a variable
Example:
query GetAccHolder($id: String = "1") {
accholder: user(id: $id) {
fullname: name
}
}
Required Variable
We can make the variable as required by appending ! to the data type
query GetAccHolder($id: String!) {
accholder: user(id: $id) {
fullname: name
}
Directives
We have already seen how we can pass the dynamic variable inside our queries. Now, we can see how to dynamically generate the query structure using directives.
Directives help to dynamically change the structure and shape of our queries using variables.
@include and @skip are the two directives available in GraphQL
Example directives:
@include(if: Boolean) — Includes the fields if it is true
query GetFollowers($id: String) {
user(id: $id) {
fullname: name,
followers: @include(if: $getFollowers) {
name
userHandle
tweets
}
}
}
{
"id": "1",
"$getFollowers": false
}
Here $getFollowers is false, hence field name followers would not be included in the response @skip(if: Boolean) — Skips the fields if it is true
query GetFollowers($id: String) {
user(id: $id) {
fullname: name,
followers: @skip(if: $getFollowers) {
name
userHandle
tweets
}
}
}
{
"id": "1",
"$getFollowers": true
}
Here $getFollowers is true, hence field name followers would be skipped (excluded) from the response
Resources
- GraphQL — The official website
Conclusion
In this article, we have learned what GraphQL is and how to compose various queries with it.
If you liked it please leave some love to show your support. Also, leave your responses below and reach out to me if you face any issues.